위 글은 nplan 이라는 프로젝트의 리스크를 예측하는 사업모델을 가진 회사의 블로그 글을 번역한 것입니다.
원문은 여기를 클릭하시면 볼 수 있습니다.
1부: 기계 대 사람
nPlan은 기계 학습을 사용하여 건설 일정의 결과를 예측함으로써 프로젝트의 위험을 예측하는 사업을 하고 있습니다. 우리는 주관성, 예측 정확도, 일정 품질, 사람들이 불확실성과 인공 지능에 대해 생각하는 방식에 대해 생각하는 데 많은 시간을 할애합니다.
사람들은 우리와 계약의 초기 단계에서 종종 두 가지 질문을 합니다.
- 어떻게 알고리즘이 위험을 예측하는 전문가보다 더 나을 수 있습니까?
- 내 고유한 프로젝트에서 알고리즘이 어떻게 작동합니까?
내 기술 경험과 조지아의 위험 분석 배경이라는 두 가지 각도에서 통찰력을 제공하면서 이 두 가지 질문을 모두 살펴보겠습니다.
1부에서는 첫 번째 질문을 다룰 것입니다.
어떻게 알고리즘이 전문가보다 나을 수 있습니까?
기계가 프로젝트 전문가를 능가할 수 있는 이유를 이해하려면 먼저 전문가가 '전통적인' 위험 관리 프로세스에 미치는 영향을 알아야 합니다. 오늘날 대부분의 전문 기관(IRM, ISO, Prince2, API 포함)은 다음 단계를 사용하여 위험 관리 처리를 규정합니다.
- Identification (식별)
- Evaluation/assessment (평가)
- Analysis (분석)
- Treatment (조치)
- Review(rinse and repeat) (리뷰)
Identification and assessment 라는 처음 두 단계에서 팀의 역할과 영향력을 살펴보는 것으로 시작할 수 있습니다.

특정 위험 이벤트가 식별되고 주관적으로 정량화되는 일반적인 위험 평가 프로세스입니다.
| Stage | Typical areas of investigation | Project teams input |
| Identification | 프로젝트는 어떤 리스크에 노출 되는가? E.g. 리스크의 근원, 어떻게, 언제 일어나나 |
과거 경험을 바탕으로 한 리스크 식별 |
| Assessment | 그 리스크들은 얼마나 크고 나쁜가? E.g. 발생 가능성, 영향 |
과거의 개인 및 집단 경험을 기반으로 가능성과 영향을 추정 |
이 프로세스는 프로젝트 규모에 관계없이 거의 모든 곳에서 동일합니다. 소규모(2,000만 파운드)에서 대규모(1,000억 파운드 이상) 계획에 이르기까지 이는 프로젝트 팀이 잠재적으로 동일한 실수를 반복하고 있음을 의미합니다. 우리는 이것이 프로젝트 지연이 수십 년 동안 '일'이었음에도 불구하고 여전히 프로젝트 지연을 보는 이유 중 하나라고 믿습니다.
문제는 우리가 여전히 사람에게 리스크의 발생 가능성과 실현됐을 때의 영향을 식별하라고 묻고 있다는 것입니다. 이것은 각 위험 항목에 대해 하나가 아닌 세 개의 주관성을 생성하고 위험 분석에 대한 입력을 엉망으로 만들 수 있는 많은 놀라운 기회를 만듭니다.
하지만 저는 최고의 터널링 팀을 보유하고 있으며 그들은 이러한 위험을 추측하는 것이 아니라 예측하고 있습니다!
슈퍼예측

이것은 아마도 인간이 확률과 위험을 추정하는 데 끔찍하다는 것을 언급하기에 좋은 시기일 것입니다. Superforecasting 이라는 책 에서 저자들은 일부 사람들이 예측을 매우 잘하는 이유를 이해하기 위해 수년간의 연구에 대해 길게 이야기하지만 대부분은 결과를 무작위로 추측하는 것보다 낫지 않습니다. 위험과 예측에 대해 진지한 사람이라면 이 책을 읽을 책 더미의 맨 위에 두는 것이 좋습니다. 그것의 tl;dr은 불확실성을 추정하는 것이 전부라는 것입니다 .자신의 추정 실적과 일치하는 방식으로 그렇게 하십시오. 예를 들어, 전문가들은 이에 대해 끔찍하고 일관되게 지나치게 자신하고 궁극적으로 잘못된 것으로 나타났습니다. 그러나 우리가 전문가를 평가하는 방식은 우리를 확증 편향에 취약하게 만들고 궁극적으로 사람들이 여러 번 연속해서 맞췄다고 칭찬함으로써 소음 속에서 신호를 찾습니다.
불확실성, 예측 및 위험
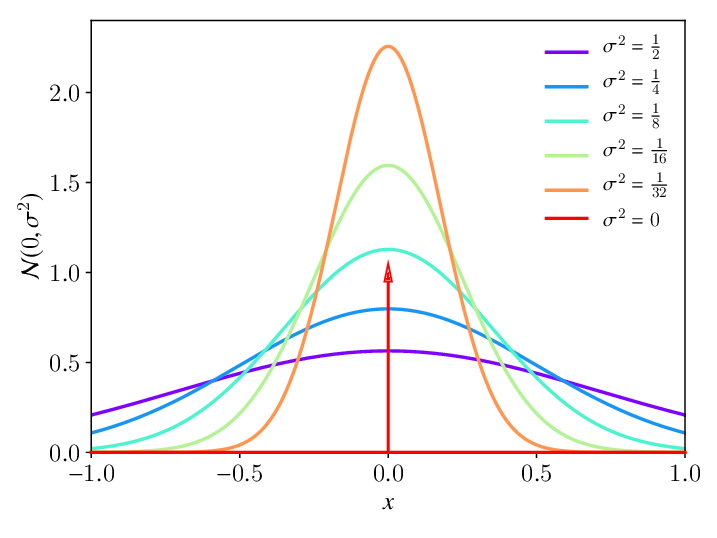
동일한 평균 값을 유지하면서 변동성과 분산의 변화에 따라 분포가 어떻게 변하는지.
미래의 사건에 대해 이야기할 때는 이 세 가지를 모두 고려해야 합니다. 그들은 함께 존재하며 영원히 얽혀 있습니다.
가능한 한 광범위하게 정의된 위험 은 의도한 계획이나 결과에서 벗어날 수 있는 가능성입니다.
예측 은 미래의 모든 사건에 대한 확률론적 관점을 생성하는 행위입니다.
불확실성 은 결과의 가변성이며 위험의 직접적인 결과입니다. 또한 예측을 생성할 때 매개변수로 포함됩니다.
위험이 높을수록 불확실성이 높을수록 예측 범위가 넓어집니다.
확률에 대한 인간의 인식
우리가 이전에 말했듯이 인간은 확률을 잘 예측하지 못합니다. 특히 작은 확률. 어떤 일이 90% 가능성이 있다면 우리 모두는 그것에 대해 매우 안전하다고 느끼는 경향이 있으며 10번 중 1번은 일이 일어나지 않을 것이라는 사실을 내면화할 수 없습니다. 우리 종의 진화에서 비롯된 사실로, 인간은 항상 지나치게 자신만만한 예측가라는 사실을 받아들이는 것이 중요합니다.

인간은 확률을 매우 다르게 인식하므로 불확실성에 대한 상충되고 부정확한 추정이 발생합니다. 이 문제에 대한 Mirko Mazzoleni의 게시물 에서 자세한 내용을 확인하세요 .
많은 사람들이 위험 관리자/분석가/엔지니어와 함께 위험 작업실에 앉아 스프레이 콘크리트 라이닝 붕괴와 같은 일종의 이벤트 확률에 대해 마음을 조사하는 것을 기억할 것입니다. " 내가 작업한 5개의 주요 터널링 작업에서 한 번 본 적이 있으므로 아마도 5분의 1 또는 20%의 확률일 것입니다." 가 여기에서 누구나 할 수 있는 최선입니다. 확률은 다를 수 있지만 더 이상 정확하지는 않습니다. 그룹 사고 및 고정(및 기타 모든 인지 편향)과 같은 효과로 팀은 시작하는 20%와 관련하여 조정할 가능성이 높으며, 이는 우리가 판단하는 방식의 또 다른 결함입니다. 이 프로세스는 우리가 추측한 모든 위험을 평가하고 추측된 확률과 영향과 결합할 때까지 반복됩니다.
그런 다음 이러한 "확률"이 몬테카를로 시뮬레이션에 추가되어 수십억 달러의 결정이 내려집니다. 멍한가요? 그럴겁니다. 매일매일 이렇게 주관적인 정보를 바탕으로 큰 재무 결정이 내려집니다! 또한 이 프로세스 에서 Black Swans 및 프로젝트 팀에 알려지지 않은 다른 모든 재앙적인 위험은 물론 추정하기 너무 어려웠던 가능성이 낮고 영향이 큰 위험을 완전히 무시 했습니다.
기계 학습 및 예측
간단히 말해서 머신 러닝은 알려진 결과로 데이터를 가져와서 특정 알고리즘 집합을 따르고 당면한 문제의 특성을 수학적 모델로 어느 정도 내면화한 모델을 생성하는 행위입니다. 이러한 모델은 이전에 볼 수 없었던 새로운 데이터에 대한 예측을 생성하는 데 사용됩니다.

확률적 예측은 연속적인 기울기에서 미래 상태(또는 더 적은 경우에는 이벤트)에 다양한 확률을 할당하므로 실무자는 추정된 분산 및 변동성이 결과에 미치는 영향에 대해 추론할 수 있습니다.
ML 모델은 관련 불확실성과 함께 예측을 생성하여 진정한 보정 을 보장하는 방식으로 생성될 수도 있습니다 . 보정된 모델은 불확실성이 정확한 모델입니다. 따라서 모델이 어떤 이벤트가 발생할 확률이 10%라고 말하면 동일한 예측을 모두 측정할 때 해당 이벤트는 10%의 확률로 발생합니다.
기계는 당신의 친구입니다
오늘날 전문가들이 따르는 프로세스에 대해 생각해 보면 두 가지 문제가 나타납니다.
- 위험에 대해 생각하는 전문가 팀은 가능한 모든 발생에 대해 생각하고 (nPlan의 경우) 프로젝트 지연에 대해 "종단 간" 관점을 취하는 대신 제한된 세트의 "잠재적" 이벤트를 제시함으로써 그렇게 하고 있습니다. 놓친 "위험"이 있다는 것은 보장됩니다.
- 인간은 타고난 과신 때문에 예측을 잘하지 못하며, 이로 인해 전통적인 예측 연습은 위험을 심각하게 과소평가하게 됩니다.
위험 관리자의 친구가 되도록 ML 모델을 훈련했습니다. 우리는 데이터 센터에서 철도에 이르는 프로젝트의 50만 개 이상의 프로젝트 일정에 대해 교육했으며, 불확실성에 대한 정확한 추정치와 함께 보정된 예측을 제공하도록 모델을 가르쳤습니다(Superforecasting을 읽은 경우 실제로 모델의 Brier Score를 측정합니다).

nPlan은 ML 모델 및 시뮬레이션 엔진의 출력을 사용하여 프로젝트 일정의 변동성을 줄이는 개선 사항을 권장합니다.
이 접근 방식은 위험 관리자와 경쟁하는 대신 의견이 아닌 데이터에서 파생된 위험 예측을 통해 권한을 부여합니다. 이를 통해 그녀는 모델이 절대 취할 수 없는 행동에 집중할 수 있습니다. 우리의 관점에서는 탐색과 결정과 같은 시간을 훨씬 더 가치 있게 사용하는 것입니다. 일정 변경 및 진행 상황 업데이트가 프로젝트 결과의 불확실성에 어떤 영향을 미치는지 이해할 수 있으므로 모든 사람이 이러한 불확실성을 사전에 줄이는 데 도움이 되고자 합니다.
불확실성이 허용 가능한 임계값 아래로 떨어지면 활동이 서로 간섭을 중지하고 일정이 "안정"되는 것을 관찰합니다. 그런 다음 CPM(Critical Path Methodology)과 같은 기존의 잘 알려진 프로젝트 관리 기술을 채택하고 프로젝트의 효율성 향상에 집중하는 것이 진정으로 효과적입니다. 왜냐하면 우리는 더 이상 급격한 변화에 영향을 받지 않기 때문입니다.
인간은 예측이 아닌 추론을 합니다. 확률에 대한 인식도 개인별로 차이가 있기 때문에 인간이 생각하는 예측의 정확도는 낮을 수 밖에 없다는 것이죠. 기계가 데이터를 통해 예측을 하는 것이 더욱 정확할 수 있다는 글이었습니다.
nPlan 사가 과거 Schedule 데이터를 어떤 방식으로 Machine learning하였고, 이를 통해 어떤 결과를 예측해 내는지가 궁금해 집니다.
'AI 인사이트 > 최신 AI 기술 리뷰' 카테고리의 다른 글
| 이제 인공지능이 PPT도 자동으로 다~작성해준답니다_Gamma App (1) | 2023.04.18 |
|---|---|
| ChatGPT에게 바르셀로나와 근교 여행에 대해 물어보았더니..! (0) | 2023.02.23 |
| 220804_오늘의 발견_doda (0) | 2022.08.04 |
| [파이썬] 여러장의 PDF 문서를 이미지로 변환하기 : 이걸로 끝남 (pdf2image) (0) | 2021.05.17 |
| [상식] 메타 + 유니버스 = 메타버스란? 쉽~게 바~로 알아가자 (0) | 2021.03.07 |




댓글