최근 구글 리서치의 31명 연구원들이 개발한 '비디오포엣(VideoPoet)'은 기존의 비디오 생성 인공지능 모델의 한계를 넘어서며, 다양한 방식으로 고품질의 동영상을 생성하는 데 성공했습니다. 이는 2억 7천만 개의 동영상 및 10억 개 이상의 텍스트-이미지 쌍 데이터로 훈련되었으며, 비디오 생성의 새로운 지평을 열고 있습니다. 지금까지 봐왔던 영상 생성과는 품질이 진일보된 모습을 보여주고 있습니다. 이에 대해 쉽지만 자세히 살펴보시죠.
요약
- 비디오포엣 개요: 구글 리서치가 개발한 '비디오포엣'은 다양한 비디오 생성 작업을 수행할 수 있는 대규모 언어 모델로, 일관된 대형 모션 생성에서의 병목 현상을 해결하고자 합니다.
- 기능과 혁신: 비디오포엣은 이미지 대 비디오, 텍스트 대 비디오, 비디오 스타일화 등 다양한 작업을 통합하며, 특히 세련된 모션과 아티팩트 없는 큰 모션 생성이 가능합니다.
- 시장 반응 및 평가: 사용자 평가에서 비디오포엣은 다른 모델에 비해 더 나은 프롬프트와 흥미로운 움직임을 생성한다고 평가되었으며, 이는 비디오 생성 분야에서 LLM의 잠재력을 시사합니다.
A vaporwave fashion dog in Miami looks around and barks, digital art.
비디오포엣이 뭐에요?
비디오포엣의 개발 배경:
비디오 생성에서의 병목 현상, 특히 대형 모션을 일관되게 생성하는 데 있어서의 어려움이 주요 동기입니다. 기존 모델들이 작은 모션 생성에는 성공했지만, 큰 모션 생성 시 아티팩트가 발생하는 문제가 있었습니다.

비디오포엣의 핵심 기술:
- 비디오포엣은 대규모 데이터에 대한 사전 학습, 텍스트 임베딩, 비주얼 및 오디오 토큰 등을 사용하여 다양한 비디오 생성 작업을 수행합니다. 이는 비디오 인페인팅, 아웃페인팅, 비디오-오디오 생성 등에 사용됩니다.

비디오포엣의 차별점:
- 다른 AI 비디오 생성 모델과 달리, 비디오포엣은 별도로 훈련된 구성 요소에 의존하지 않고 단일 LLM 내에 여러 비디오 생성 기능을 원활하게 통합합니다. 이를 통해 텍스트, 이미지, 비디오, 오디오 등 다양한 입력으로부터 직관적이고 창의적인 출력을 생성할 수 있습니다.

사용자 평가 및 시장 반응:
- 사용자들은 비디오포엣 생성된 비디오를 다른 모델보다 높게 평가했으며, 특히 텍스트 충실도와 모션 흥미도에서 높은 선호도를 보였습니다. 이는 비디오포엣이 비디오 생성 분야에서 기존의 한계를 넘어서는 가능성을 가지고 있음을 나타냅니다.
비디오포엣이 열어갈 창의적인 미래
우리는 지금 상상만 했던 미래가 바로 눈앞에 펼쳐지는 것을 목도하고 있습니다. '비디오포엣'은 단순한 기술의 진보를 넘어, 우리의 상상력을 현실로 만드는 마법사와 같죠. 그럼, 이 마법사가 실제 세계에서 어떻게 활약하고 있으며, 앞으로 어떤 놀라운 일을 할 수 있을지 함께 살펴보겠습니다.
창의력을 현실로 만드는 실제 적용 사례
1. 광고업계의 혁신:
짧은 형식의 광고 콘텐츠 생성에 비디오포엣을 활용하면, 기업들은 더욱 창의적이고 맞춤화된 캠페인을 빠르고 경제적으로 제작할 수 있습니다.
2. 교육의 변화
복잡한 개념이나 이론을 시각적으로 표현하여 학습자들의 이해를 돕습니다. 생생한 시각 자료는 교육의 질을 한 단계 끌어올리는 열쇠가 될 거예요.
3. 엔터테인먼트의 새 지평:
가상현실 게임이나 영화에서 비디오포엣이 만들어낸 풍부한 시각적 경험은 사용자들에게 전례 없는 몰입감을 선사할 것입니다.
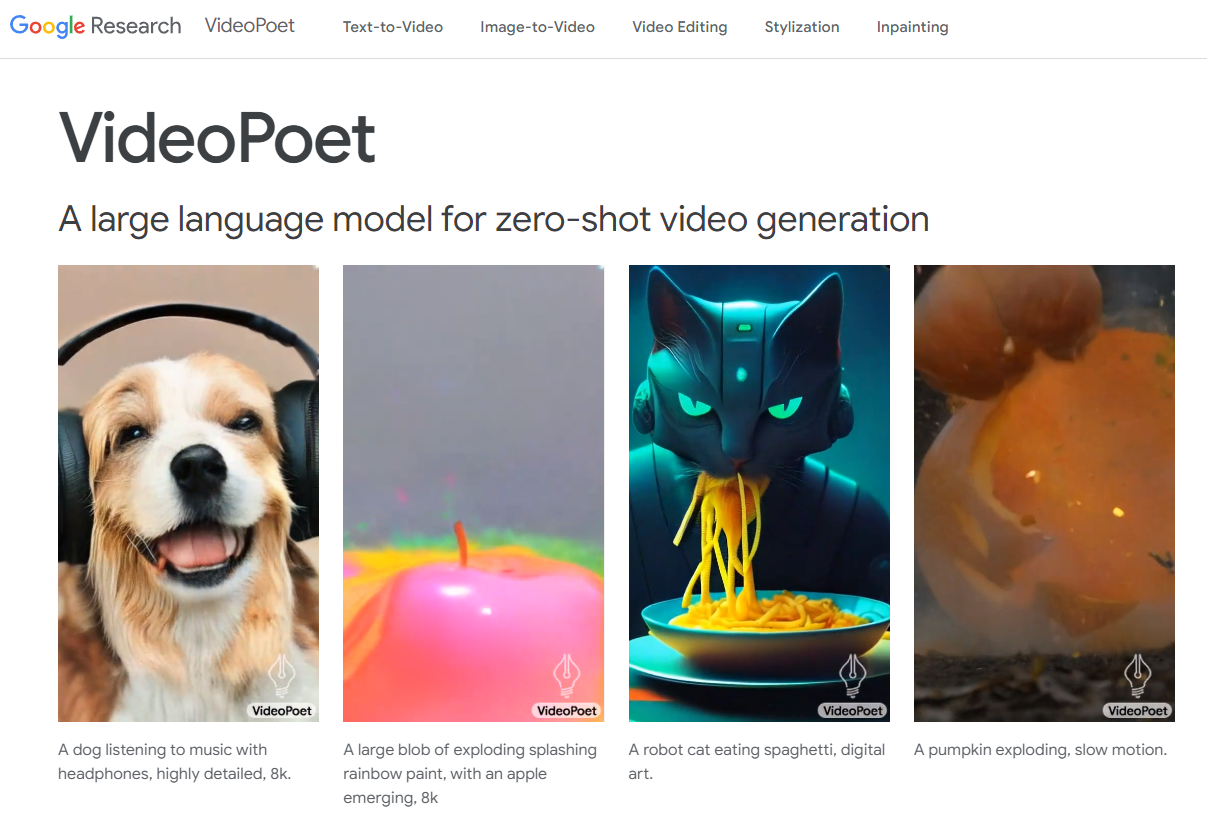
VideoPoet
A large language model for zero-shot video generation
흥미진진한 미래 전망
1. 더욱 섬세한 표현 가능:
앞으로 비디오포엣은 더욱 정교한 모션, 표정 인식을 통해 인간의 감정과 미묘한 움직임까지 포착할 수 있게 될 것입니다. 우리의 감정을 스크린 속 캐릭터와 완벽하게 동기화시키는 날이 오겠죠!
2. 실시간 비디오 생성
실시간으로 반응하며 생성되는 비디오는 라이브 방송, 온라인 교육, 게임 등 여러 분야에서 혁신을 가져올 것입니다. 상상만 해도 가슴이 두근거리지 않나요?
3. 윤리적 사용과 규제
기술의 발전은 우리에게 새로운 책임을 부여합니다. 비디오포엣과 같은 강력한 도구의 윤리적 사용과 규제에 대한 논의는 우리 사회가 함께 풀어가야 할 중요한 숙제이죠.
'비디오포엣'의 등장은 비디오 생성 분야에서 중요한 이정표로, 창의적이고 다채로운 콘텐츠 제작에 새로운 장을 열었습니다. 이처럼 기술이 끊임없이 진화함에 따라, 우리는 더욱 풍부하고 생생한 디지털 세계를 기대할 수 있겠죠. 앞으로도 비디오포엣과 같은 혁신이 계속해서 등장하기를 기대합니다!
마지막으로 VideoPoet이 생성한 영상들을 감상해보시죠.
Two pandas playing cards.
A squirrel in armor riding a goose, action shot.
A horse galloping through Van Gogh's 'starry night'
A chicken lifting weights.
Two raccoons on motorbikes. A meteor shower falls behind the raccoons. The meteors impact the earth and explode.
#비디오포엣 #GoogleResearch #AI비디오생성 #LLM #언어모델 #동영상기술 #AI혁신 #모션생성 #아티팩트 #비디오인페인팅 #비디오아웃페인팅 #오디오비디오 #디지털콘텐츠 #창의성 #기술진화 #멀티태스킹 #비디오스타일화 #텍스트비디오 #이미지비디오 #사용자평가 #비디오품질 #흥미로운모션 #고품질동영상
'AI 인사이트 > 최신 AI 트렌드' 카테고리의 다른 글
| 현대백화점의 디지털 전환 "일하는 방식을 AI로 바꿔라" 가상의 대화로 알아보자. (0) | 2024.04.08 |
|---|---|
| 회사에 RAG 과제 제안을 준비하며 든 생각들 (2) | 2024.02.06 |
| 딥마인드의 멀티모달 AI Gemini 잼민이? 출시 정보 정리합니다. 이것만 보면 됨. (0) | 2023.12.07 |
| DALL-E3 이제 Midjourney에게 안밀릴듯(feat.슈퍼파워 AI 동키..!!!) (2) | 2023.11.28 |
| Langchain은 사실 실제 서비스에는 적합하지 않습니다. 그 이유는요.. (랭체인 DIY의 한계 정리, RAG 챗봇 개발 유의점) (0) | 2023.11.23 |




댓글