이번 글에서는,
AIMMO에서 Annotation(라벨링) 한 json 파일을 제대로 읽어보겠다.
이 json 파일은 초보의 눈에 매우 복잡한 구조를 띄었다.
이걸 어떻게 딥러닝을 위한 데이터 셋으로 변환할 수 있을까?
아주 시작부터 위기다!
한번 차근차근 풀어가 보자.
AIMMO에 대해 소개를 한번 드려야겠다.
AIMMO는 딥러닝 데이터 가공을 위한 온라인 Annotation 툴이다.
아래에서 보듯이 정말 쉽고, 빠르고, 정확하게 데이터 가공 업무를 처리할 수 있는 '플랫폼'이다.

AI 데이터 솔루션- AIMMO
고품질 데이터를 쉽게, 빠르게!
aimmo.co.kr
아직 초보라 잘 모르지만, 초보임에도 매우 쉽게 쓸 수 있었으니, 매우 만족한다.
문제
하지만 여기서 문제가 있었으니,
AIMMO에서 작업한 산출물이 json 파일로 나온 것이다.
사실 개발자 출신도 아니고, 공부를 열심히 한 것도 아니라서 솔직히 json이 뭔지도 몰랐다.
한걸음 한걸음 걸어가다보면 언젠가는 다다르겠지.. -타이거
그래, 천천히 가자. 천천히 갈 수록 많이 보인다.
그래서, json이 무엇이며 어떻게 python에서 읽고, 쓰고, 인코딩하고, 디코딩 하는지에 대해 공부했고, 이제 어느정도 감을 잡았다. (아직 모르신다면 아래 글을 참고)
[딥러닝 첫걸음] python에서 json 파일 읽기
인공지능 AIMMO 라는 클라우드 소싱으로 이미지 라벨링을 할 수 있는 서비스가 있다. 여기에서 작업한 라벨링 결과물이 json파일로 추출되었다. 그렇다면 이제 이걸 python에서 읽어야 한다. json 파
lapina.tistory.com
AIMMO 이미지 라벨링 출력물
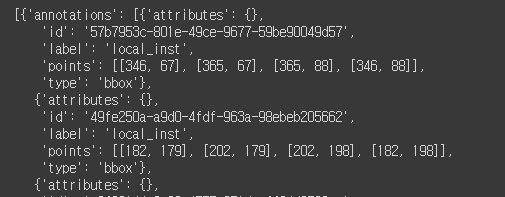

하..정말 복잡하다. 눈에 안들어온다.
이건 마치 정체불명의 네스호의 괴물 같다.

하지만 나는 할 수 있다. 힘을내어 자세히 들여다 보자.
특징을 살펴 본다.
우선 [ ] 대괄호로 시작한다. 그 말은 리스트 타입이란 말이다.

결국 이 징그러운 데이터도 알고보면 아주 거대한 리스트인 것이다!!!
자 그러면 다음을 살펴보자.
리스트 안에 곧바로 { } 중괄호가 나온다. 중괄호는 dict 즉 딕셔너리 타입이다.
딕셔너리는 이런 형태이다.
tiger_dict ={'이름':'타이거', '나이:12', '폰번호':'비밀'}
파이썬은 리스트 안에 딕셔너리가 들어가고, 딕셔너리 안에 또 리스트가 들어가게 가능한 언어 '인가보다' 아아아~~!!


결국 나는.. 이 의문의 괴물에 대해 알아버렸다.
피부가 있고 살이 있고 뼈가 있다.
리스트 안에 딕셔너리가 들어있고, 그 안에 또 리스트가 들어있다.
그 말인 즉슨, 문제를 풀 수 있다는 말이다. 하하하!!!
왕초보 파이썬 책으로도 해결할 수 있는 문제라는 말씀. 후후후...
책이 없으신 분들은 이거 보시면 좋아요! 아래 사진 클릭

자 그럼 딕셔너리의 키를 한번 살펴볼까?
local_inst[0].keys()dict_keys(['annotations', 'attributes', 'file_id', 'filename', 'parent_path', 'last_modifier_id'])
이미지 라벨링의 결과물 답게
annotations, attributes, file_id, filename, parent_path, last_modifier_id 를 볼 수 있다.
여기서 내가 필요한 정보는 뭘까..
?annotation만 있으면 될까?
?path와 file_name도 필요할까?
사실 모른다!!!
일단 annotation 정보만 추출해버리겠다.
일단 이번편의 주제는 읽기 였으니까, 읽은걸로 마무리 짓겠다.
다음편에서 계속하겠다.
'개발 이야기 > 머신러닝, 딥러닝' 카테고리의 다른 글
| [딥러닝 첫걸음] 생에 첫 컴퓨터 비전, OpenCV야 안녕? OpenCV로 이미지 열어버리기 (5) | 2021.03.05 |
|---|---|
| [딥러닝 첫걸음] 미션!! AIMMO에서 딥러닝을 위한 이미지 라벨링 산출물 JSON 파일 변형하기 (0) | 2021.03.05 |
| [딥러닝 첫걸음] python에서 json 파일 읽기 (0) | 2021.03.04 |
| Jupyter notebook 실행 시 Bad file descriptor 오류 (25) | 2021.03.04 |
| [개발도구] Visual Studio Code 사용법 모음 (0) | 2020.02.26 |




댓글