Object Detection(물체 검출) 모델의 성능 평가는 Precision-Recall 곡선과 Average Precision(AP)로 평가한다.
각 용어를 쉽고 자세하게 이해해 보는 시간을 가져보자.
Keyword : Precision, Recall, Confusion Matrix, PR Curve, IoU, Interpolation, AP, mAP
Precision과 Recall의 이해
Precision은 정밀도를 뜻하고, Recall은 재현율을 뜻한다. 하나씩 자세히 알아보자.
1. Precision (정밀도)
Precision은 모든 검출 결과 중 옳게 검출한 비율을 의미한다. 이는 다음과 같은 식으로 표현할 수 있다.

TP : True Positive = 검출한 결과가 옳은 것 = 기계가 맞다고 한게 맞은것
FP : False Positive = 검출한 결과가 틀린 것 = 기계가 맞다고 한게 틀린 것
위의 용어 이해를 바탕으로 위 식을 보면 이는 전체 검출 결과 중 옳은 검출의 비율을 의미한다.
10개 중 9개를 옳게 검출했으면 0.9 가 되는 것이다.
2. Recall (재현율)
Recall은 마땅히 검출해내야 하는 물체들 중에서 제대로 검출된 비율을 뜻한다. 공식을 살펴보자.

FN : False Negative = 검출 되었어야 하는 물체인데 검출 되지 않은 것 = 기계가 못찾은 것
즉, 옳게 검출한 것과 옳게 검출한 것과 검출 못한것의 합의 비율이다.
예를들면 라벨이 붙어있는 물체가 10개인데 그 중 4개가 옳게 검출 되었다면 recall은 4/10 = 0.4가 된다.
용어를 정리 해 보면 아래의 테이블과 같다. 아래의 테이블은 Confusion Matrix라고 한다.

Confusion Matrix란 Binary Classifier의 Prediction결과를 2X2 Matrix로 표현한 것이다.
Confusion Matrix의 Element는 다음과 같이 정의된다.
1) 첫번째 Term : Prediction과 Ground Truth의 일치 여부로 True/False를 정한다.
2) 두번째 Term : Prediction 결과에 따라 Positive/Negative를 정한다.
IoU(Intersection over Union)의 이해
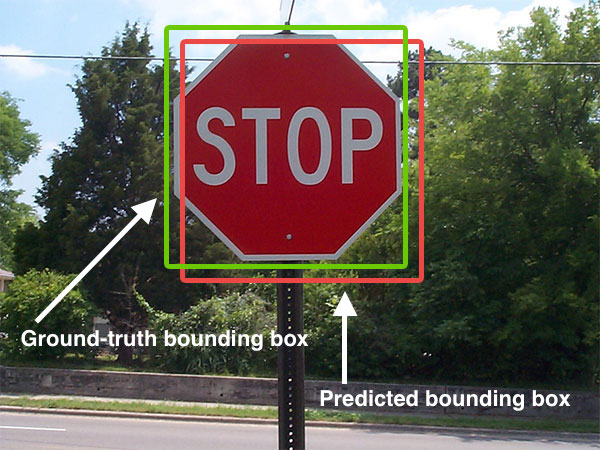
아래와 같이 ground truth 바운더리 박스를 라벨로 가진 이미지가 있다고 가정해 보자. ground truth 바운더리 박스는 마땅히 검출되어야 할 물체를 감싸고 있다.

이 이미지의 ground truth Boundary box가 가 주어지지 않은 상황에서 어떤 알고리즘에 의해 예측 된 Boundary Box가 다음과 같다고 가정하자.

이 때 알고리즘이 검출한 Boundary box가 맞는지 틀린 지를 결정하기 위해 나온것이 IoU이다.
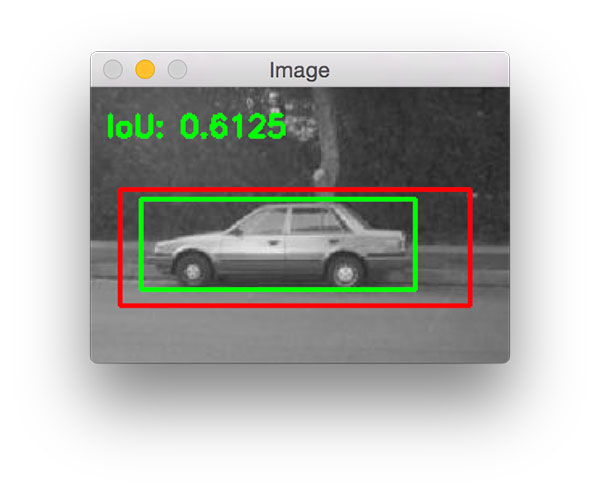
IoU는 아래의 공식으로 구해 진다.

예측된 Boundary box와 사용자가 설정한 Boundary box 간 중첩되는 교집합 부분의 면적을 측정해서 중첩된 면적을 합집합의 면적으로 나눠 주는 공식이다.
IoU의 계산 결과가 0.5 이상이면 제대로 검출 되었다고 판단한다. (True Positive) 만약 0.5 미만이면 잘못 검출 되었다고 판단한다.(False Positive)
IoU > 0.5 = TP
IoU < 0.5 = FP
아래의 사진도 참고해 보자.


Precision-Recall 곡선
PR 곡선은 confidence 레벨에 대한 threshold 값의 변화에 의한 물체 검출기의 성능을 평가하는 방법이다. 여기에서 confidence 레벨은 검출한 것에 대해 알고리즘이 얼마나 확신이 있는지를 알려주는 값이다.
참고로 confidence 레벨이 높다고해서 무조건 검출이 정확한 것은 아니다. 그저 기계 스스로가 자신이 있다는 의미일 뿐인 것이다. 따라서 알고리즘의 사용자는 보통 confidence 레벨에 대해 threshold 값을 부여해서 특정값 이상이 검출되어야 검출 된 것으로 인정한다. threshold 값이 0.4라면 confidence 레벨로 0.1 또는 0.2를 갖고 있는 검출은 무시하게 된다.
따라서 이 confidence 레벨에 대한 threshold 값의 변화에 따라 precision과 recall 값들도 달라질 것이다. 이것을 그래프로 나타낸 것이 바로 PR 곡선이다.
이해가 아직은 어려우므로 예시를 살펴보자.
15개의 얼굴이 존재하는 어떤 데이터셋에서 한 얼굴 검출 알고리즘에 의해서 총 10개의 얼굴이 검출(confidence 레벨 0부터 100까지 모두 고려했을 때) 되었다고 가정해보자. 이 때 각 검출의 confidence 레벨과 옳게 검출 되었는지 잘못 검출 되었는지에 대한 여부는 아래 표에 나타냈다.
이제 TP, FP가 뭔지는 잘 알고 있다.
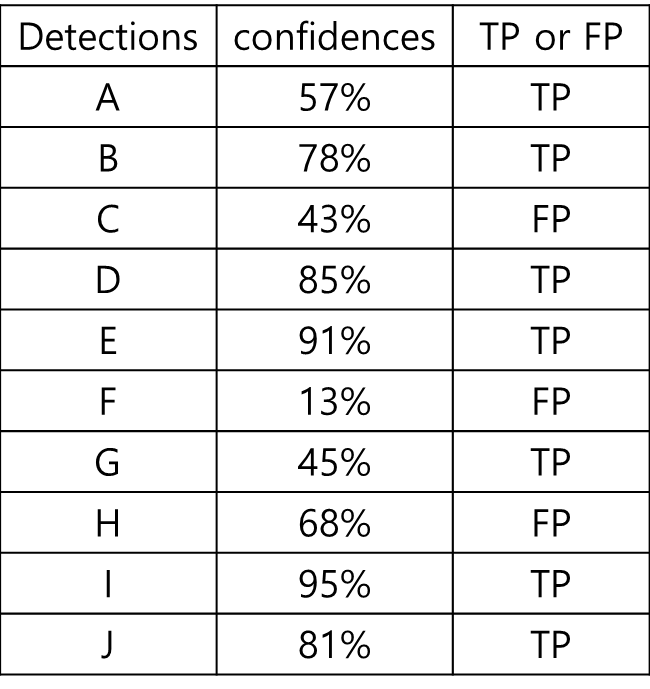
10개 중 7개가 제대로 검출되었고, 3개는 잘 못 검출되었다.
이 때,
Precision = 옳게 검출된 얼굴 갯수/검출된 얼굴 갯수 = 7/10 = 0.7이 되고,
Recall = 옳게 검출된 얼굴 갯수/실제 얼굴 갯수 = 7/15 = 0.47이 된다.
이것은 Confidence 레벨이 13%와 같이 아주 낮더라도 검출해낸 것은 모두 인정했을 때의 결과이다.
이번에는 결과 테이블을 confidence 레벨에 따라 재정렬 해본다.
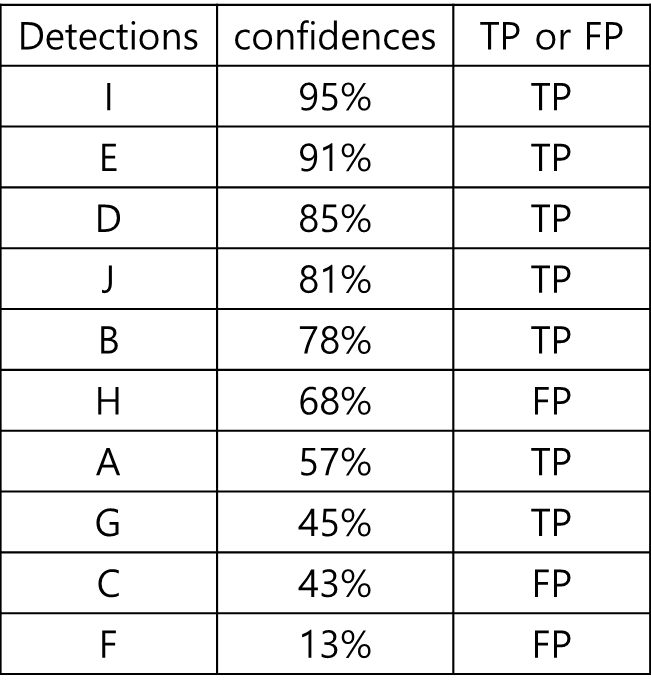
confidence 레벨에 대한 threshold값을 아주 엄격하게 적용해서 95%로 했다면, 하나만 검출한 것으로 판단할 것이고, 이 때 Precision = 1/1 = 1, Recall = 1/15 = 0.067이 될 것이다. threshold를 91%로 했다면 두개가 검출된 것으로 판단할 것이고, Precision = 2/2 = 1, Recall = 2/15 = 0.13dl ehlsek.
threshold 값을 검출들의 confidence 레벨에 맞춰 낮춰가면 다음과 같이 precision과 recall이 계산된 표가 나온다.
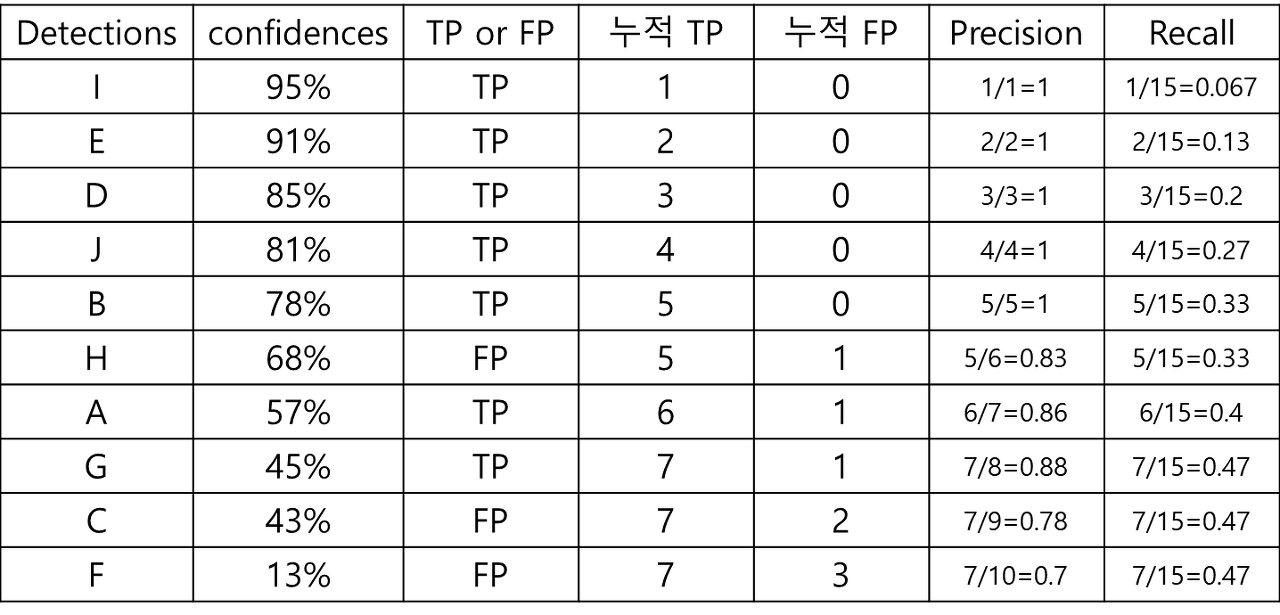
이 Precision 값들과 Recall 값들을 아래와 같이 그래프로 나타내면 그것이 바로 PR 곡선이 된다.

PR곡선에서 X축은 recall 값이고, Y축은 precision 값이다. 즉, PR곡선에서는 recall 값의 변화에 따른 precision 값을 확인할 수가 있다.
Average Precision (AP)
precision-recall 곡선은 어떤 알고리즘의 성능을 전반적으로 파악하기에는 좋으나 서로 다른 두 알고리즘의 성능을 정량적으로 비교하기에는 불편한 점이 있다. 그래서 나온 개념이 Average Precision이다. Average Precision은 인식 알고리즘의 성능을 하나의 값으로 표현한 것으로 precision-recall 곡선에서 그래프 선 아래 쪽의 면적으로 계산 된다. Average Precision이 높으면 높을 수록 그 알고리즘의 성능이 전체적으로 우수하다는걸 의미한다. 컴퓨터 비전 분야에서 물체인식 알고리즘의 성능은 대부분 Average Precision으로 평가한다.
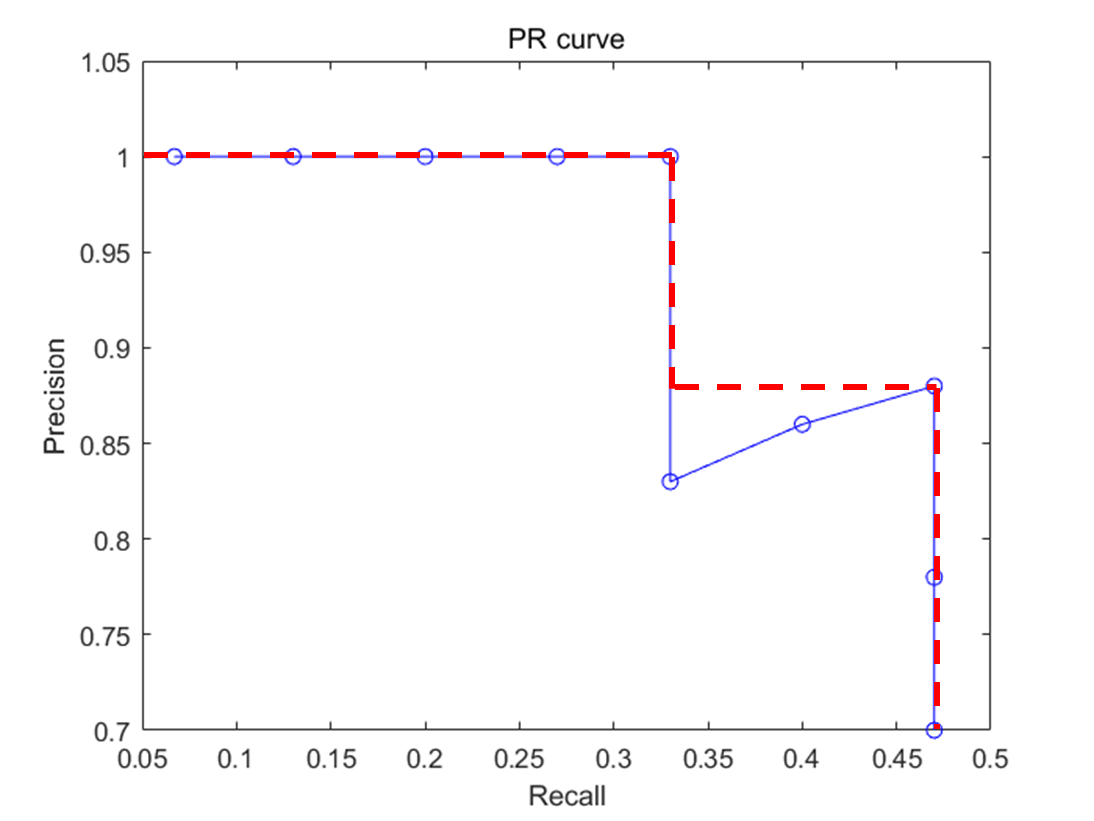
보통 계산 전에 PR 곡선을 살짝 손봐 준다. PR 곡선을 단조적으로 감소하는 그래프로 표현하기 위해 위와 같이 바꿔 준다. 이를 Interpolation(보간법) 이라고 한다. 보간법에 대한 설명은 여기에 잘 나와있다.(iskim3068.tistory.com/35)
그 다음 그래프 선 아래의 넓이를 계산한다.
위의 경우
AP = 위쪽 큰 사각형의 넓이 + 오른쪽 작은 사각형의 넓이
= 1 * 0.33 + 0.88*(0.47-0.33) = 0.4532 가 된다.
컴퓨터 비전 분야에서 물체 검출 및 이미지 분류 알고리즘의 성능은 대부분 이 AP로 평가한다.
물체 클래스가 여러개인 경우 각 클래스당 AP를 구한 다음에 그것을 모두 합한 다음 물체 클래스의 갯수로 나눠줌으로 알고리즘의 성능을 평가한다. 이것을 mAP(mean Average Precision)라고 한다.
maP를 구하는 잘 작동하는 파이썬 코드는 여기서 다운받을 수 있다.(https://github.com/Cartucho/mAP)
정리하자면,
- AP (Average Precision) : Recall value [0.0, 0.1, …, 1.0] 값들에 대응하는 Precision 값들의 Average 이다.
- mAP (mean Average Precision) : 1개의 object당 1개의 AP 값을 구하고, 여러 object-detector 에 대해서 mean 값을 구한 것이 mAP 이다.
즉 mAP란 mutiple object detection 알고리즘에 대한 성능을 1개의 scalar value로 표현한 것이다.
정리
마지막으로 mAP를 구하는 순서를 정리 해보자.
1. Precision - Recall 곡선을 그린다.
2. Threshold를 0으로 정해 놓고 detection 알고리즘을 모든 test 이미지에 돌린다.
3. Bounding-box에 해당하는 confidence score와 true positive/false positive 여부를 결정한다.
4. Pair를 confidence 레벨값에 따라 내림차순으로 정렬한다.
5. Interpolated Precision-recall 값을 구한다.
6. AP를 구한다.
7. mAP를 구한다.
장점 1 : 인식 Threshold에 의존성없이 성능평가가 가능하다.
장점 2 : mAP 평가를 통해 최적 threshold를 정할 수도 있다.
단점 : 굉장히 느리다. 아무래도 모든 Test Image에서 threshold 0 이상의 box를 추출하고 정렬하는 과정을 거쳐야 하기 때문.
위의 내용을 이해 했다면 이제 Object detection 알고리즘들의 성능이 어떤지 어느정도 파악할 수 있지 않을까 싶다.
실제 코드에 적용해 보며 내 알고리즘을 평가해 볼일만 남았다.



Reference
mAP(Mean Average Precision) 정리
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습
ctkim.tistory.com
보간(Interpolation)이란
컴퓨터 비전에서 기본적으로 꼭 알아야할 보간. 보간(Interpolation)이란 ①새로운 점을 만들기 위해 수많은 점들을 평균화시키는 것. 이 방법은 샘플점들을 직선으로 연결하지 않고 곡선으로 연결
iskim3068.tistory.com
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾
bskyvision.com
Keyword : Precision, Recall, Confusion Matrix, PR Curve, IoU, Interpolation, AP, mAP
이 글을 통해 위의 키워드들의 이해도가 높아졌길 바래본다.
필자도 꾸준한 학습과 다양한 시도를 통해 이를 내 머릿속에 때려 박아야 겠다.
감사합니다.
'개발 이야기 > 머신러닝, 딥러닝' 카테고리의 다른 글
| 파이썬 리스트에서 특정 문자열을 포함한 원소와 원소의 인덱스를 찾는 법 (1) | 2021.05.26 |
|---|---|
| [딥러닝 첫걸음] YOLOv4 삽질_CUDA 버전, cudart64_110.dll CuDNN , tensorflow 버전 문제 (3) | 2021.05.13 |
| [딥러닝 첫걸음] OpenCV - dilate, erode (수학적 형태학) 쉽게 이해하고 넘어가기 (0) | 2021.03.11 |
| [딥러닝 첫걸음] 파이썬 OCR 라이블러리 - pytesseract로 OCR 해보기(이미지 문자 읽기) (7) | 2021.03.11 |
| [딥러닝 첫걸음] Colab에서 tesseract-ocr 라이브러리 사용하려면 (0) | 2021.03.11 |




댓글